
나는 축산전공자였고, 이번에 정처기를 새롭게 준비하고 있다.
비전공자가 타 전공의 기사시험을 취득하려면 새로운 정보들을 빠르게 습득해야한다. 그러기 위해서는 각자만의 방식으로 이해하는 것이 굉장히 중요하다.
내 방식은 누구에게 알려주듯 글을 쓰는 것이다.
일단 새로 얻은 지식들을 초벌굽기하듯 이해하고, 나중에 맛나게 요리해보리라.
자료구조(Data Structure)는 컴퓨터 상 자료를 효율적으로 저장하기 위해 만들어진 논리적인 구조이다.
자료구조의 분류에는
선형 구조와 비선형 구조가 있다.
선형 구조에는
리스트(List), 스택(Stack), 큐(Queue), 데크(Deque; Double Ended Queue)가 있다.
비선형 구조에는
트리(Tree), 그래프(Graph)가 있다.
먼저 선형구조들부터 알아보자.
리스트(List)

선형리스트는 단순히 자료를 나열해놓은 자료구조이다.
간편하지만 데이터의 수정이 까다로워 질 수 있는 단점이 있다.
아래의 연결리스트는 데이터와 링크(포인터)를 합친 노드를 각각 연결해놓은 것이다.
주소 참조가 참 쉬워지겠다.
포인터를 통해 찾는 시간이 추가되므로 자료 찾는 시간은 선형 리스트 대비 다소 늦을 수 있다.
스택(Stack)과 큐(Queue)

스택(Stack)!!!
어디서 많이 들어봤다.
나는 롤을 많이 했었다. 주 라인은 탑이었고 나서스를 주로 플레이 했었다.
스택쌓는게 참 재미있었기 때문이다.
저 스택도 나서스의 스택과 다를바 없다.
마지막에 들어온 값이 제일 처음에 나간다 (Last in First Out)
미니언 막타를 쳐서 스택을 3씩 쌓아올린뒤(Push), 나를 괴롭히던 티모의 뚝배기를 스택을 터트려 깠을 때(Pop!!) 그 쾌감. 굳.
여기서, Push 연산은 스택에 데이터를 차례대로 쌓는 것이고
Pop연산은 가장 위에 있는 데이터를 하나씩 꺼내는 연산이다.
스택의 자료 삽입 삭제 코드는 아래와 같다.
삽입
If Top = n Then
Overflow
Else {
Top = Top +1
insert S(TOP)
}
삭제
If Top = 0 Then
Underflow
Else {
remove S(TOP)
Top = Top - 1
}
오버플로우와 언더플로우가 일어나는 이유는
C언어를 공부할 때 배웠었다.
역시 지식은 돌고 돌아 전부 쓸모있다.
큐(Queue)는 한쪽 끝에서는 삽입 작업이 이루어지고
반대쪽 끝에서는 삭제 작업이 이루어진다.
First in First Out 형식의 자료구조이다.
이때 Queue로 들어가는 것은 ENQUEUE
Queue를 나가는 것은 DEQUEUE.
데크(Deque; Double Ended Queue)
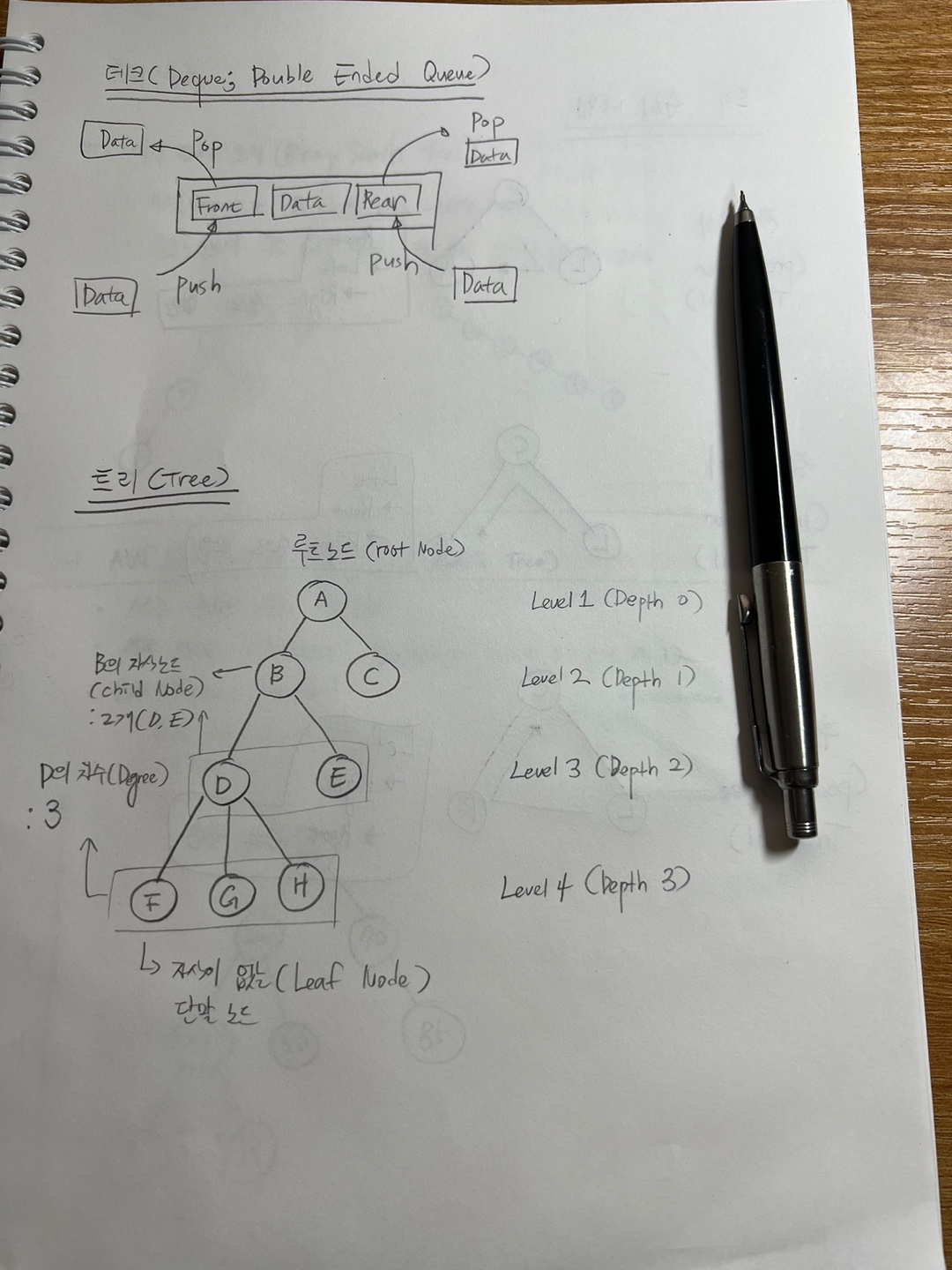
데큐!!
Queue인데 양쪽 끝이 터미널이라
양 끝에서 Push와 Pop이 동시에 일어난다.
비선형 구조
트리(Tree)
위에 트리도 같이 적어놨다.
트리는 데이터들을 계층화 시켜놓은 자료구조이며, Node(동그란거)와 Branch(뻗어나가는 가지)로 이루어져 있다.
또한 노드끼리 Cycle은 형성되어있지 않다.
인덱스를 조작하는 방법으로 가장 많이 사용하는 구조이다.
배열과 달리 노드들이 포인터로 연결되어 노드의 상한선이 없다.
트리 순회 방법

트리 순회 방법이다.
전위 중위 후위는 뜻을 그냥 보면 잘 익혀진다.
다만 왼쪽부터 이루어진다는 것은 다소 흥미로운데
스타크래프트 유즈맵을 만들 때 모든 트리거가 왼쪽부터 시작한 것을 보면
아마도 이것과 관련이 있지 않을까 싶다.
그래프

그래프의 설명은 생략한다.

그래프의 탐색 방법이다.
하나는 깊이를, 하나는 넓이를 우선적으로 탐색한다.
'했던것들 > 정보처리기사' 카테고리의 다른 글
| 속성 C언어 : Switch문 (0) | 2022.04.12 |
|---|---|
| 정보처리기사/프로그래밍 언어 활용/서버 프로그램 구현(보안 취약성, API) 및 배치프로그램 (0) | 2022.04.12 |
| 정보처리기사/프로그래밍 언어 활용/공통 모듈 구현 (0) | 2022.04.12 |
| 정보처리기사/프로그래밍 언어 활용/서버 프로그램 구현 (0) | 2022.04.12 |
| 정보처리기사/데이터베이스 구축 (0) | 2022.04.11 |