
시니어님께서 보내주신 링크인데 영어로 되어있어 번역해가며 공부해보고자 합니다.
https://proandroiddev.com/the-real-repository-pattern-in-android-efba8662b754
The “Real” Repository Pattern in Android
Over the years I’ve seen many implementations of the repository pattern, yet I think most of them are wrong and not beneficial.
proandroiddev.com
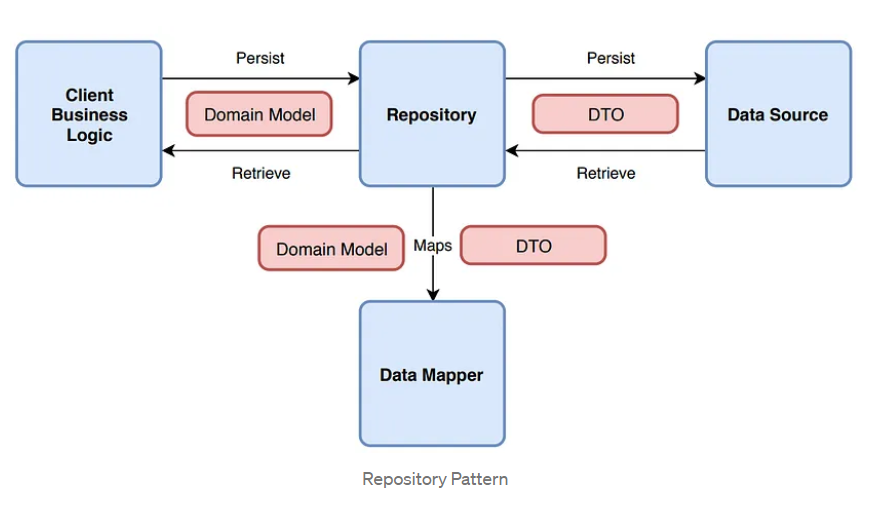
몇 년간 필자는 리포지토리 패턴을 많이 보아왔지만, 많은 사람들이 이 패턴을 잘못 구현하거나, 별로 이익이 되지 않게 구현하고 있던걸 확인할 수 있었습니다.
리포지토리(Repository) 패턴에서 사람들이 실수하는 것들은 아래와 같습니다.
- 리포지토리가 도메인 모델(Domain Model) 대신 DTO*를 리턴하는 것.
- 데이터소스(DataSources : ApiServices, Daos... 등등)가 같은 DTO를 사용하는 것.
- 엔드포인트마다 리포지토리가 있고, 엔티티마다 리포지토리가 없는 경우.
- 리포지토리가 모든 모델을 캐싱하는 경우. (언제나 최신 상태여야하는 필드가 포함되어 있음에도 불구하고)
- 데이터소스가 하나 이상의 리포지토리에서 사용되고 있을 경우
* DTO : Data Transfer Object (데이터 전송을 위해 생성되는 객체)
You need a Domain Model (당신은 도메인 모델이 필요하다.)
필자는 도메인 모델은 리포지토리 패턴의 키포인트이고, 개발자들이 도메인이 뭔지 잘 모르기 때문에 리포지토리 패턴 구현에 어려움을 겪는다고 생각합니다.
Martin Fowler는 도메인 모델을 아래와 같다고 언급했습니다.
"행동(behavior)과 데이터(data)를 포함하는 도메인의 오브젝트 모델"
즉, 도메인 모델은 기업 전반에 걸친 비즈니스 규칙을 나타낸다고 할 수 있습니다..
도메인 주도 디자인(DDD; Domain Driven Design) 빌딩 블록이나 계층적 아키텍쳐 (Hexagonal, Onion, Clean... 등)에 익숙치 않은 분들을 위해 3개의 도메인 모델이 있습니다.
- 엔티티(Entity) : ID를 가지고 있으며, 가변적일 수 있는 객체입니다.
- Value object : ID가 없는 불변적인 객체입니다.
- 집합 루트(Aggregate root, DDD에서만 사용) : 다른 엔티티와 결합된 엔티티입니다. (즉, 관련된 객체들의 모음)
간단한 도메인에서는 이러한 모델들이 데이터베이스와 네트워크 모델(DTO)과 매우 유사하지만, 여전히 많은 차이가 있습니다.
- 도메인 모델은 데이터와 프로세스를 결합하며, 앱에 가장 적합한 구조를 지니고 있습니다.
- DTO는 JSON/XML 요청(request)/응답(response) 또는 데이터베이스 테이블의 객체 모델 표현이므로, 원격 통신(remote transition)에 가장 적합한 구조를 띄고 있습니다.
아래는 도메인 모델의 예시입니다. (코틀린)
// Product.kt
// Entity
data class Product(
val id: String,
val name: String,
val price: Price,
val isFavourite: Boolean
) {
// Value object
data class Price(
val nowPrice: Double,
val wasPrice: Double
) {
companion object {
val EMPTY = Price(0.0, 0.0)
}
}
}
아래는 DTO의 예시입니다.
// NewworkProduct.kt
// Network DTO
data class NetworkProduct(
@SerializedName("id")
val id: String?,
@SerializedName("name")
val name: String?,
@SerializedName("nowPrice")
val nowPrice: Double?,
@SerializedName("wasPrice")
val wasPrice: Double?
)// DBProduct.kt
// Database DTO
@Entity(tableName = "Product")
data class DBProduct(
@PrimaryKey
@ColumnInfo(name = "id")
val id: String,
@ColumnInfo(name = "name")
val name: String,
@ColumnInfo(name = "nowPrice")
val nowPrice: Double,
@ColumnInfo(name = "wasPrice")
val wasPrice: Double
)보시다시피 도메인 모델은 프레임워크와 상관없이 구성되며, 멀티화된 어트리뷰트(Price에서 볼 수 있듯이 논리적으로 그룹화된)를 촉진하고, Null 오브젝트 패턴(필드는 null이 될 수 없음)을 사용합니다. 반면 DTO는 프레임워크(Gson, Room)와 결합됩니다.
이러한 분리 덕분에
- 앱 개발이 쉬워집니다. null을 확인할 필요가 없어지고, 멀티값을 갖는 속성 덕분에 전체 모델을 사용할 필요가 없게 해줍니다.
- 데이터 소스의 변경이 상위 레벨 정책(high-level policies)에 영향을 미치지 않습니다.
- god model(갓 모델 : 여러 비즈니스 로직이 모인 엔티티)을 피함으로써 관심사 분리가 더 잘 이루어집니다.
- 나쁜 백엔드의 구현이 상위 레벨 정책에 영향을 미치지 않습니다. (예를 들어, 백엔드가 단일 요청으로 필요한 모든 정보를 제공하지 못하여 2개의 네트워크 요청을 수행해야 하는 경우, 이 문제가 전체 코드베이스에 영향을 미치게 두어야 할까요?)
You need a Data Mapper (당신은 데이터 매퍼가 필요하다.)
데이터 매퍼는 DTO를 도메인 모델로 매핑하고, 그 반대도 (도메인모델을 DTO로) 수행하는 곳입니다.
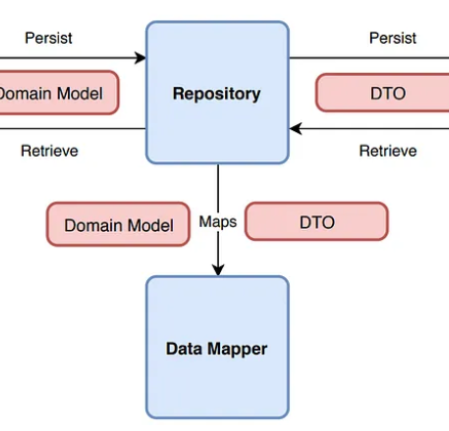
대부분의 개발자들은 이러한 매핑을 지루하고 불필요한 것으로 생각해서
데이터 소스에서부터 UI까지 모두 DTO와 결합하는 것을 선호합니다.
이는 (아마도) 처음 릴리즈를 더 빠르게 제공하기 때문에 유용할 수 있지만, 도메인 레이어를 건너 뛰고 UI를 데이터 소스와 연결하면, 제품에서만 발견되는 여러 버그가 발생할 수 있습니다. (예: 백엔드가 빈 문자열 대신 null을 보내서 NPE*가 생성되는 경우).
이 외에도 비즈니스 규칙과 유스케이스를 프레젠테이션 레이어에 숨기는 경우도 있습니다. (예: 스마트 UI 패턴*).
필자 의견으로는, 매퍼는 빠르게 작성하고 간단하게 테스트할 수 있습니다.
비록 매퍼의 구현이 지루할지라도, 매퍼는 데이터 소스가 변경되었을 때 이로 인해 발생할 수 있는 예기치 않은 문제를 예방해줄 수 있습니다.
매핑에 시간이 없거나 매핑을 원하지 않는 경우, 객체 매핑 프레임워크를 사용할 수 도 있습니다.
하지만 보일러플레이트 코트를 줄이기위해서 + 보통의 구현에서는 프레임워크를 사용하지 않는 편이 좋을 수 있습니다.
아래는 제가 사용하는 방법입니다.
// Mapper.kt
interface Mapper<I, O> {
fun map(input: I): O
}- I가 들어오면 O를 리턴하는 mapper 방식입니다.
그리고 각각의 특정 리스트 to 리스트 매핑을 구현하는 것을 피하도록 하는 일련의 일반적인 ListMapper도 있습니다.
// ListMapper.kt
// Non-nullable to Non-nullable
interface ListMapper<I, O>: Mapper<List<I>, List<O>>
class ListMapperImpl<I, O>(
private val mapper: Mapper<I, O>
) : ListMapper<I, O> {
override fun map(input: List<I>): List<O> {
return input.map { mapper.map(it) }
}
}// NullableInputListMapper.kt
// Nullable to Non-nullable
interface NullableInputListMapper<I, O>: Mapper<List<I>?, List<O>>
class NullableInputListMapperImpl<I, O>(
private val mapper: Mapper<I, O>
) : NullableInputListMapper<I, O> {
override fun map(input: List<I>?): List<O> {
return input?.map { mapper.map(it) }.orEmpty()
}
}// NullableOutputListMapper.kt
// Non-nullable to Nullable
interface NullableOutputListMapper<I, O>: Mapper<List<I>, List<O>?>
class NullableOutputListMapperImpl<I, O>(
private val mapper: Mapper<I, O>
) : NullableOutputListMapper<I, O> {
override fun map(input: List<I>): List<O>? {
return if (input.isEmpty()) null else input.map { mapper.map(it) }
}
}- (( 2DC : 이건 아직 이해가 가지 않습니다. ))
You need a different model for each DataSource
(데이터 소스마다 각각 다른 모델들이 필요하다.)
네트워크나 데이터베이스에 단 하나의 모델만 사용하면 아래의 코드와 같게 됩니다.
// ProductDTO.kt
@Entity(tableName = "Product")
data class ProductDTO(
@PrimaryKey
@ColumnInfo(name = "id")
@SerializedName("id")
val id: String?,
@ColumnInfo(name = "name")
@SerializedName("name")
val name: String?,
@ColumnInfo(name = "nowPrice")
@SerializedName("nowPrice")
val nowPrice: Double?,
@ColumnInfo(name = "wasPrice")
@SerializedName("wasPrice")
val wasPrice: Double?
)위의 코드가 두개의 다른 모델을 가지는 것 보다 더 빠르다고 생각할 수 있습니다.
하지만 위의 방법에서 위험성을 보실 수 있나요?
위 코드의 몇가지 위험성에 대해 나열해보겠습니다.
- 필요 이상으로 캐시할 수 있습니다.
- 응답에 필드를 추가하면 데이터 마이그레이션이 필요합니다.
- 새로운 필드를 생성하지 않는 한, 이전 타입과 동일한 데이터 유형이어야 합니다.
(예를들어, nowPrice라는 문자열을 파싱하여 double을 캐시할 수는 없습니다.)
즉, 별도의 모델을 가지는 것 보다 유지관리에 더 많은 노력이 필요하다는 것 입니다.
You should cache only what you need (필요한 것만 캐시해라)
- 원격 카탈로그에 저장되어 있는 제품 리스트의 제품을 화면에 보여주고 싶고,
- 각 제품에는 로컬 위시리스트에 해당 제품이 있을 경우 클래식 하트 아이콘을 달아주고 싶다고 해봅시다.
위의 요구조건에 따라 우리는 필요한 로직이 아래와 같다고 이해할 수 있습니다.
- 제품 리스트를 Fetch 해오기.
- 로컬 스토리지의 로컬 위시리스트에 제품이 있는지 체크해보기
이에 따른 우리의 도메인 모델은 이전과 같지만, 위시리스트에 해당 제품이 있는지 여부를 나타내는 필드를 추가할 수 있을 것입니다.
// Entity
data class Product(
val id: String,
val name: String,
val price: Price,
val isFavourite: Boolean
) {
// Value object
data class Price(
val nowPrice: Double,
val wasPrice: Double
) {
companion object {
val EMPTY = Price(0.0, 0.0)
}
}
}
이 경우, 우리의 네트워크 모델은 이전과 같이 보존될 것이지만, 데이터베이스 모델은 더이상 필요하지 않습니다.
로컬 위시리스트의 경우, 우리는 단순히 product의 id를 SharedPreferences에 저장할 수 있습니다.(안드로이드 얘기인 듯 합니다.) 데이터베이스 마이그레이션 문제를 처리하고 이를 복잡하게 만드는 대신 간단한 작업을 위한 로직을 만들면 됩니다.
마지막으로 우리의 리포지토리는
// ProductRepositoryImpl.kt
class ProductRepositoryImpl(
private val productApiService: ProductApiService,
private val productDataMapper: Mapper<DataProduct, Product>,
private val productPreferences: ProductPreferences
) : ProductRepository {
override fun getProducts(): Single<Result<List<Product>>> {
return productApiService.getProducts().map {
when(it) {
is Result.Success -> Result.Success(mapProducts(it.value))
is Result.Failure -> Result.Failure<List<Product>>(it.throwable)
}
}
}
private fun mapProducts(networkProductList: List<NetworkProduct>): List<Product> {
return networkProductList.map {
productDataMapper.map(DataProduct(it, productPreferences.isFavourite(it.id)))
}
}
}
사용된 디펜던시는 다음과 같이 정의할 수 있습니다.
// Components.kt
// A wrapper for handling failing requests
sealed class Result<T> {
data class Success<T>(val value: T) : Result<T>()
data class Failure<T>(val throwable: Throwable) : Result<T>()
}
// A DataSource for the SharedPreferences
interface ProductPreferences {
fun isFavourite(id: String?): Boolean
}
// A DataSource for the Remote DB
interface ProductApiService {
fun getProducts(): Single<Result<List<NetworkProduct>>>
fun getWishlist(productIds: List<String>): Single<Result<List<NetworkProduct>>>
}
// A cluster of DTOs to be mapped into a Product
data class DataProduct(
val networkProduct: NetworkProduct,
val isFavourite: Boolean
)
이제, 우리가 로컬 위시리스트에 관련된 제품만 가져오고 싶다면 어떻게 하면 될까요?
이 경우 구현은 단순할 것입니다.
// ProductRepositoryImpl.kt
class ProductRepositoryImpl(
private val productApiService: ProductApiService,
private val productDataMapper: Mapper<DataProduct, Product>,
private val productPreferences: ProductPreferences
) : ProductRepository {
override fun getWishlist(): Single<Result<List<Product>>> {
return productApiService.getWishlist(productPreferences.getFavourites()).map {
when (it) {
is Result.Success -> Result.Success(mapWishlist(it.value))
is Result.Failure -> Result.Failure<List<Product>>(it.throwable)
}
}
}
private fun mapWishlist(wishlist: List<NetworkProduct>): List<Product> {
return wishlist.map {
productDataMapper.map(DataProduct(it, true))
}
}
}
마치며
필자는 이 패턴을 전문적인 수준에서 여러 번 사용해본 경험이 있습니다.
특히 큰 프로젝트에서는 생명의 구원자 역할을 한다고 합니다.
그러나 많은 경우, 개발자들이 이 패턴을 "해야 한다" 라는 이유로 사용하기도 하지만, 이 패턴이 가진 실제 이점을 알지 못하는 경우가 많습니다.
이 글이 여러분에게 흥미롭고 유용했기를 바랍니다.
'했던것들 > 알게된 것들' 카테고리의 다른 글
| 반성할 점 (0) | 2023.03.16 |
|---|---|
| 내가 생각해본 타입스크립트를 배워야 하는 이유 (5) | 2023.03.14 |
| 네이버 Map 타입스크립트 적용하기 (0) | 2023.03.13 |
| 소켓 연결 이슈 (0) | 2023.03.06 |
| ESLint, Prettier 통합 (0) | 2023.02.27 |