
리포지토리 패턴
유지보수가 쉬운 코드 구조를 구현하는 방법은 제각각이지만 추구하려는 목표는 '코드의 응집도 증가와 결합도 감소'로 대부분 같다. 이를 위해서는 복잡한 로직을 가진 코드 뭉텅이를 여러 개의 레이어나 클래스로 분리하는 작업이 필연적일 수 밖에 없다. 아래 그림을 보자. A는 복잡한 로직이 하나의 레이어에 뭉쳐있는 것을 표현한 것이고 B는 복잡한 기능들을 레이어로 나눠놓은 것이다.
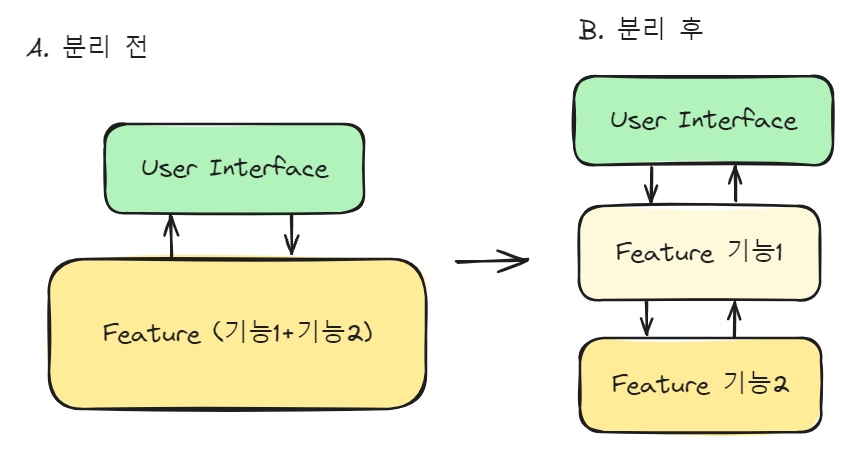
A의 경우, 간단한 코드를 작성할 때 유리한 방식이다. 그러나 본질적으로 코드의 결합도가 높을 수밖에 없으므로 복잡한 기능을 구현해야할 때나 기능이 점차적으로 스케일업 되어야 하는 경우에는 작업량에 따라 수많은 에러와 유지보수 비용 증가가 발생할 것이다.
B의 경우, 간단한 코드를 작성함에 있어서 사실상 시간적인 손해가 생길 수도 있다. 그러나 A에 비해 기능 결합도가 상대적으로 낮고 기능1과 기능2가 서로 잘 응집되어 있으므로, 복잡한 기능을 구현해야 하거나 기능의 점진적인 스케일업이 필요할 때는 A에 비해서 작업이 상당히 수월할 것이다.
리포지토리 패턴은 B 패턴과 상당히 흡사한 패턴이다.
다만 리포지토리 패턴은 데이터 접근 로직을 분리한다는 것에 초점을 둔다.
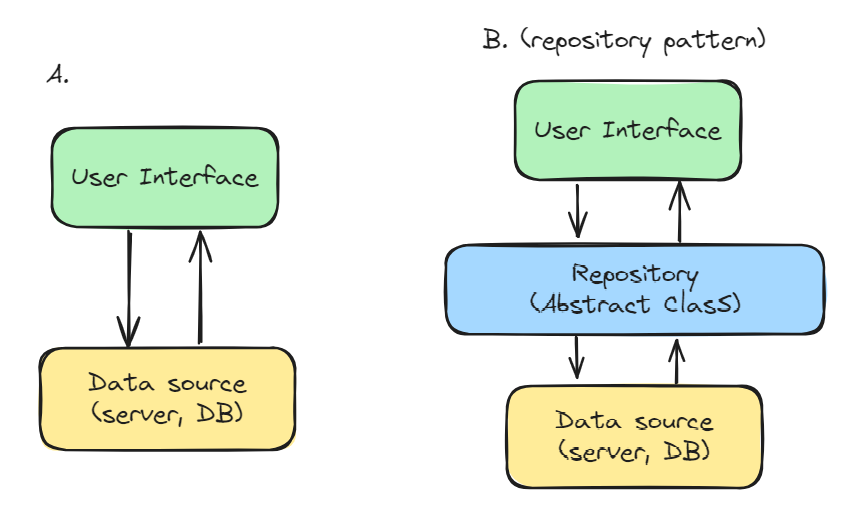
UI에서 별도의 추상화 계층 없이 데이터소스로 바로 요청을 보내는 경우, 요청에 상응하는 응답도 UI가 바로 받게 된다. 사실 이상할 것은 없는 구조지만, UI는 데이터 요청 외에도 수많은 역할을 하고 있으므로 분리할 수 있는 기능은 분리해주는 것이 좋다. 즉 UI의 비즈니스 모델이 데이터소스를 직접적으로 호출하지 않게 만드는게 관건이다.
UI에서 직접 데이터소스에 요청을 보내 응답을 받을 경우, 때때로 유지보수가 굉장히 복잡해지는 상황이 발생할 수 있다. 예를 들어 동료가 연차를 낸 상황에서 동료가 만든 UI의 데이터 요청 로직에 오류가 생겼다고 가정해보자. 나는 동료가 만든 데이터 요청 로직 오류를 해결하기 위해 동료가 짠 UI의 로직들을 모두 이해해야 할 것이다. 만약 UI를 충분히 이해하지 못한 상태에서 데이터소스 관련 코드를 수정할 경우, 예측하지 못한 사이드이펙트가 야기될 수 있다.
반면 UI와 데이터소스 사이에 데이터 엑세스 계층만 관리하는 리포지토리 레이어가 추가되었다고 가정해보자. 이 경우, 데이터 요청에 문제가 생기더라도 이전처럼 UI 전체 로직을 파악할 필요성이 사라진다. 리포지토리 레이어와 데이터소스 레이어에 어떤 오류가 있는지만 확인하면 되기 때문이다.
즉 프론트엔드 리포지토리 패턴의 핵심은 UI가 데이터 엑세스 로직을 알고있을 필요가 없다는 것으로 정의할 수 있다.
리포지토리 패턴의 필요성이 느껴졌다면 본격적으로 리포지토리 패턴을 구현해보자.
구현
모두가 쉽게 코드를 해석하고 사용할 수 있도록 바닐라 타입스크립트로 구현했다.
구조를 잘 이해하고 있다면 다른 프레임워크로 이식하는 것은 크게 어렵지 않을 것이다.
https://github.com/2duckchun/vanila-repository-pattern
GitHub - 2duckchun/vanila-repository-pattern: 리포지토리 패턴 구현.
리포지토리 패턴 구현. Contribute to 2duckchun/vanila-repository-pattern development by creating an account on GitHub.
github.com
(구현 코드가 담긴 깃허브 리포지토리)
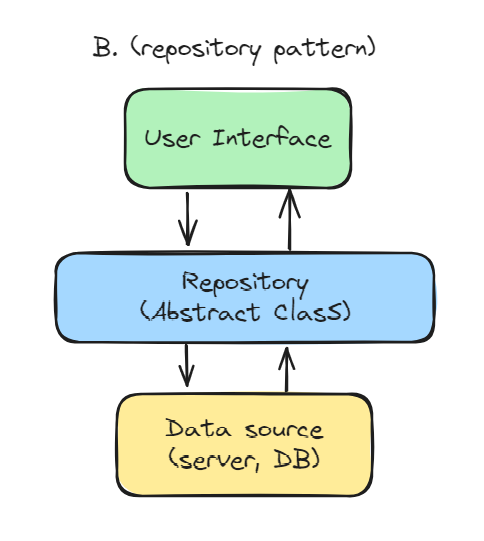
위와 같은 계층 구조를 만들기 위해 아래의 순서대로 구현할 것이다.
- 데이터 정의
- 데이터소스 클래스 구현
- 리포지토리 클래스 구현
- UI에서 리포지토리 호출
1. 데이터 정의
https://jsonplaceholder.typicode.com/
JSONPlaceholder - Free Fake REST API
{JSON} Placeholder Free fake and reliable API for testing and prototyping. Powered by JSON Server + LowDB. Serving ~3 billion requests each month.
jsonplaceholder.typicode.com
코드 예시에서는 jsonplaceholder의 posts 배열을 데이터로 정의하여 사용하고자 한다.
// index.ts
type PostDTO = {
userId: number;
id: number;
title: string;
body: string;
};
type Post = {
userId: number;
postId: number;
title: string;
content: string;
};
type FetchErrorMessage = {
message: string;
status: number;
};
가장 먼저 어떤 데이터를 사용할지부터 정의해야 한다. fetch를 통해 받아올 DTO의 타입과 내가 UI에서 사용할 데이터의 타입, 에러시 반환할 데이터 타입 등을 미리 정의하면 될 듯 하다. 해당 예시에서는 타입을 아래와 같이 정의했다.
- type PostDTO : jsonplaceholder에 fetch를 보냈을 때 받아올 수 있는 DTO이다.
- type Post : UI에서 사용할 데이터 타입으로, PostDTO를 파서 함수로 가공한 객체이다. DTO 파싱은 리포지토리 레이어에서 진행된다. 리포지토리 레이어에서 DTO를 파싱한 후 UI에 전달해줌으로써 UI와 데이터소스의 결합은 사실상 끊기게 된다.
- type FetchErrorMessage : 단순 에러처리 용도의 데이터로써, 통신간 에러가 발생했을 때 UI로 전달할 객체이다.
2. 데이터소스 클래스 구현
interface IPostDatasource {
getPostList(): Promise<PostDTO[]>;
}
export class PostDatasource implements IPostDatasource {
private readonly token?: string;
constructor(token?: string) {
this.token = token;
}
async getPostList(): Promise<PostDTO[]> {
try {
// fetch 실행
const response = await fetch(
"https://jsonplaceholder.typicode.com/posts",
{
method: "GET",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${this.token}`,
},
cache: "no-store",
}
);
// fetch는 성공했으나, 응답이 ok가 아닐 경우
if (!response.ok) throw new Error("postDatasourse is NOT 200");
// fetch에 성공했고 응답도 ok인 경우 받아온 데이터를 그대로 반환
const result: PostDTO[] = await response.json();
return result;
} catch (error) {
// fetch 자체에서 에러가 날 경우
// 에러를 그대로 리턴해줘도 repository에서 캐치해낸다.
console.error("🐜PostDatasource ERROR: ", error);
throw error;
// 또는 필요에 따라 에러 생성자로 에러메세지를 새롭게 만들어도 된다.
// throw new Error("에러가 났어요~")
}
}
}
구현 순서
- 인터페이스에 데이터소스 클래스를 정의한다.
- 인터페이스를 바탕으로 클래스를 구현한다.
- token을 어떻게 취급할 것인지 미리 생각해두어야 한다. 모든 데이터 접근에 토큰이 필요한 것은 아니나, 토큰을 필요로하는 데이터 접근이 있을 수 있다. 따라서 데이터소스 클래스 인스턴스를 생성할 때 토큰을 주입받을 수 있도록 생성자에 미리 파라미터를 추가하는 등의 방법을 강구해둔다.
데이터소스 클래스는 서버(데이터엑세스) 계층과 직접적으로 맞닿아있는 클래스로써 실질적으로 데이터를 외부로부터 가져오는 역할을 하며, 특별한 일이 없다면 리포지토리 패턴의 장점을 극대화하기 위해 데이터를 페칭해오는 역할만 가지고 있어야 한다.
3. 리포지토리 클래스 구현
import { PostDatasource } from "./post-datasource";
interface IPostRepository {
getPostList(): Promise<Post[] | FetchErrorMessage>;
}
export class PostRepository implements IPostRepository {
private readonly datasource: PostDatasource;
constructor(private readonly token?: string, datasource?: PostDatasource) {
this.datasource = datasource ?? new PostDatasource(token);
}
async getPostList() {
try {
const result = await this.datasource.getPostList();
return this.PostDTOParser(result);
} catch (error) {
return {
message: "getPostList에 문제가 생겼습니다.",
status: 500, // 백엔드와 이야기해서 합의한 status를 error에서 받을 수 있음.
};
}
}
PostDTOParser = (data: PostDTO[]): Post[] => {
return data.map((el) => ({
userId: el.userId,
postId: el.id,
title: el.title,
content: el.body,
}));
};
}
구현 순서
- 인터페이스에 리포지토리 클래스를 정의하고, 인터페이스를 바탕으로 클래스를 구현한다. 이 과정까지는 데이터소스 클래스를 구현하는 방법과 동일하다.
- 차이점은 리포지토리 클래스는 데이터소스 클래스로부터 의존성을 주입받아 사용된다는 점이다.
- 의존성 주입을 통해 얻을 수 있는 장점 중 하나는 테스팅이 쉽다는 것이다. 데이터소스 클래스와 1:1 매핑되는 테스팅 클래스를 만들어 그대로 리포지토리 클래스에 의존성으로 주입하면 리포지토리 클래스는 테스트 기능을 훌륭히 수행하는 레이어가 된다.
리포지토리 클래스는 다른 클래스로부터 인스턴스를 주입 받아야만 제대로 동작할 수 있는 클래스이다. 또한 어떤 의존성을 주입받느냐에 따라 수행할 수 있는 역할이 달라진다.
이 외에도 페칭이 성공했을 시 데이터소스로부터 받아오는 DTO를 UI에서 사용하는 객체로 파싱해주는 파서 함수를 달아놓는 것이 필요하다. 파서를 통해 DTO와 UI의 직접적인 연결을 끊어줌으로써 UI와 데이터소스간의 결합도를 낮춰줄 수 있다.
4. UI에서 리포지토리 호출
// index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<div id="app"></div>
<script type="module" src="/src/main.ts"></script>
</body>
</html>// main.ts
import { PostRepository } from "./modules/post/post-repository";
class UI {
async drawPostListUI() {
const getPostData = async () => {
const result = await new PostRepository().getPostList();
return result;
};
const data = await getPostData();
document.querySelector<HTMLDivElement>("#app")!.innerHTML = `
<h1>리포지토리 패턴 실습</h1>
<div>
${
Array.isArray(data) &&
data.map((el) => {
return `
<section style='border: 3px solid teal'>
<div>${el.userId}</div>
<div>${el.title}</div>
<div>${el.content}</div>
</section>
`;
})
}
</div>
`;
}
}
new UI().drawPostListUI();
- UI에서 리포지토리 클래스 인스턴스를 호출하여 필요한 데이터를 받아 화면에 렌더링한다.
- UI는 리포지토리 호출 외에는 따로 신경쓸 것이 없으므로, 데이터 엑세스에 관한 코드 수정을 할때는 UI를 아예 생각에서 배제할 수 있다.
- 무언가를 만들기위해 고려해야할 상황을 줄인다는 것은 작업 효율성 증대로 이어진다. 결과적으로 복잡한 데이터 엑세스 작업을 수행할수록 리포지토리 패턴의 사용은 빛을 발할 것이다.
리포지토리 패턴의 단점
리포지토리 패턴을 도입했을 때 얻을 수 있는 장점으로는 앞서 설명했듯이 코드의 응집도 증가와 결합도 감소를 꼽을 수 있다. 그러나 완벽한 설계는 없듯이 리포지토리 패턴에도 단점이 있다. 내가 생각한 리포지토리 패턴의 단점은 아래와 같다.
- 간단한 프로젝트를 만드는 것에는 적절치 못한 패턴이다. 데이터 엑세스가 얼마 없는 프로젝트를 설계하는데 굳이 리포지토리 패턴을 도입할 필요는 없다. 오히려 작업 속도만 늦춰질 뿐이다.
- 러닝커브가 있다. 이 개념을 사용하기 위해서는 어느정도의 개발 지식이 필요한 것 같다. 특히 이 구조의 필요성을 직접 느끼고 설계하려면 약간의 실무 경험이 필수적으로 필요한 것 같다.
마치며
사실 나에게 있어 리포지토리 패턴은 개발 인생에서 처음 만난 통곡의 벽이었다. 바야흐로 개발 0년차. fetch는 그냥 UI단에서 시원하게 갈기는 것이 아닌가? 라고 생각해왔던 내게 이런 패턴은 너무 괴롭고 어려웠다.
그래도 찰나의 경험이 쌓이다보니, 위 패턴은 생각보다 그렇게 복잡한 패턴은 아니고 오히려 큰 규모의 프로젝트를 설계하는데 있어서 어느정도 필수적일 수 있겠다고 생각이 드는 좋은 패턴이었다. 역시나 아는만큼 보인다. 경험을 쌓고 성장해서 더 큰 규모의 프로젝트를 설계하고 구현할 수 있는 기회를 만나보고 싶다.
'개발 일지' 카테고리의 다른 글
| gitlab) runner has never contacted this instance (1) | 2024.05.27 |
|---|---|
| VSCode에서 소스 코드 저장 시 eslint + prettier가 동작하지 않는 경우 (0) | 2024.04.07 |
| Nextjs 프로젝트 설계 이모저모 - 과도기적 디렉토리 설계 (2) | 2024.02.08 |
| Nextjs 프로젝트 설계 이모저모 - 집합적 사고로 레이아웃 설계하기 (0) | 2024.01.29 |
| 프론트엔드 설계 아이데이션 (0) | 2024.01.12 |